IDP Showdown: DocDigitizer vs IQBOT
Introduction to Accounts Payable Automation
Accounts payable automation refers to using technology to streamline and optimize the accounts payable process.
The accounts payable process involves various tasks such as invoice processing, approval, and payment, and can be time-consuming and prone to errors when done manually.
Accounts payable automation seeks to reduce manual intervention and automate many of these tasks, resulting in increased efficiency, accuracy, and cost savings.
The automation of accounts payable typically involves the use of software tools such as optical character recognition (OCR), robotic process automation (RPA), and artificial intelligence (AI) to digitize, process, and manage invoices.
For example, OCR technology can scan and extract data from invoices, while RPA can automate tasks such as data entry and invoice routing. AI can be used to identify patterns and anomalies in invoice data, flagging any potential errors or fraud.
Accounts payable automation can offer several benefits to organizations, including:
- Faster processing times: Automation can significantly reduce the time it takes to process invoices, from receipt to payment.
- Increased accuracy: Automation can help to eliminate errors that are common in manual processing, such as data entry mistakes.
- Cost savings: Automation can reduce the costs associated with invoice processing, such as manual labor and paper-based processes.
- Improved supplier relationships: Faster processing times and improved accuracy can help to strengthen supplier relationships by reducing payment delays and errors.
- Better financial control: Automation can help organizations to better manage their cash flow and improve financial reporting by providing real-time visibility into accounts payable data.
Intelligent Document Processing (IDP) and AP Automation
Intelligent Document Processing (IDP) can help accounts payable automation in several ways. IDP uses a combination of technologies such as Optical Character Recognition (OCR), Machine Learning (ML), and Natural Language Processing (NLP) to automate the extraction of information from documents, including invoices, receipts, and purchase orders. Here are some ways IDP can help accounts payable automation:
- Faster invoice processing: IDP can automate the extraction of data from invoices, reducing the time and effort required to manually enter data. This speeds up the invoice processing time and allows for quicker payment processing.
- Improved accuracy: IDP can accurately extract data from invoices and automatically validate it against business rules, reducing the chance of errors and eliminating the need for manual data entry.
- Cost savings: By automating the invoice processing and data extraction tasks, IDP reduces the need for manual labor, saving costs associated with manual invoice processing.
- Greater visibility and control: IDP provides real-time access to invoice data, allowing for better tracking and control over the accounts payable process.
- Reduced fraud: IDP can flag potential fraudulent invoices based on anomalies detected in the data, such as unusual invoice amounts or payment terms.
Overall, IDP can significantly improve accounts payable automation by reducing manual intervention, increasing accuracy, and providing greater visibility and control over the accounts payable process. With IDP, organizations can streamline their invoice processing, reduce costs, and free up resources for more strategic tasks.
Invoice Processing Challenges
While Intelligent Document Processing (IDP) can offer several benefits to accounts payable automation, there are also some challenges that organizations may face when implementing IDP to process invoices. Here are some of the main challenges:
- Variability in invoice formats: Invoices can come in various formats, layouts, and structures, making it challenging for IDP systems to extract information accurately. IDP systems need to be trained on different invoice formats and variations to handle such variability.
- Limited accuracy of OCR: OCR technology, which is used in IDP, may not always accurately recognize and extract data from invoices, especially if they contain poor quality images or non-standard fonts. Errors in OCR can lead to errors in the data extracted, leading to incorrect payments or other issues.
- Complex invoice data: Invoice data can be complex, with multiple line items, taxes, and discounts. IDP systems need to be able to accurately extract this data and validate it against business rules, which can be challenging.
- Integration with existing systems: Integrating IDP with existing systems, such as Enterprise Resource Planning (ERP) or accounting software, can be challenging. The IDP system needs to be able to seamlessly transfer data to and from these systems.
- Cost: Implementing IDP can be costly, especially if the organization needs to invest in new technology or hire specialized personnel to manage the system.
- Privacy and security concerns: Processing invoices involves sensitive financial and personal data, which requires strict privacy and security protocols. IDP systems need to ensure the security of the data processed, stored, and transferred.
Processing Invoices with IQBOT (Automation Anywhere)
Here is a step-by-step tutorial on how to use IQBOT to process invoices:
Step 1: Login to IQBOT
Firstly, you need to login to the IQBOT application with your credentials. If you don’t have an account, you can sign up for one..
Step 2: Create a new workflow
Once you’re logged in, create a new workflow by clicking on the “New Workflow” button. You can name the workflow anything you like.
Step 3: Upload the invoices
After creating a new workflow, you need to upload the invoices that you want to process. You can do this by clicking on the “Upload Files” button and selecting the invoices from your computer.
Step 4: Define the extraction rules
Once the invoices are uploaded, you need to define the extraction rules. Extraction rules are a set of instructions that tell the IQBOT system what information to extract from the invoices. To create extraction rules, click on the “Define Extraction Rules” button.
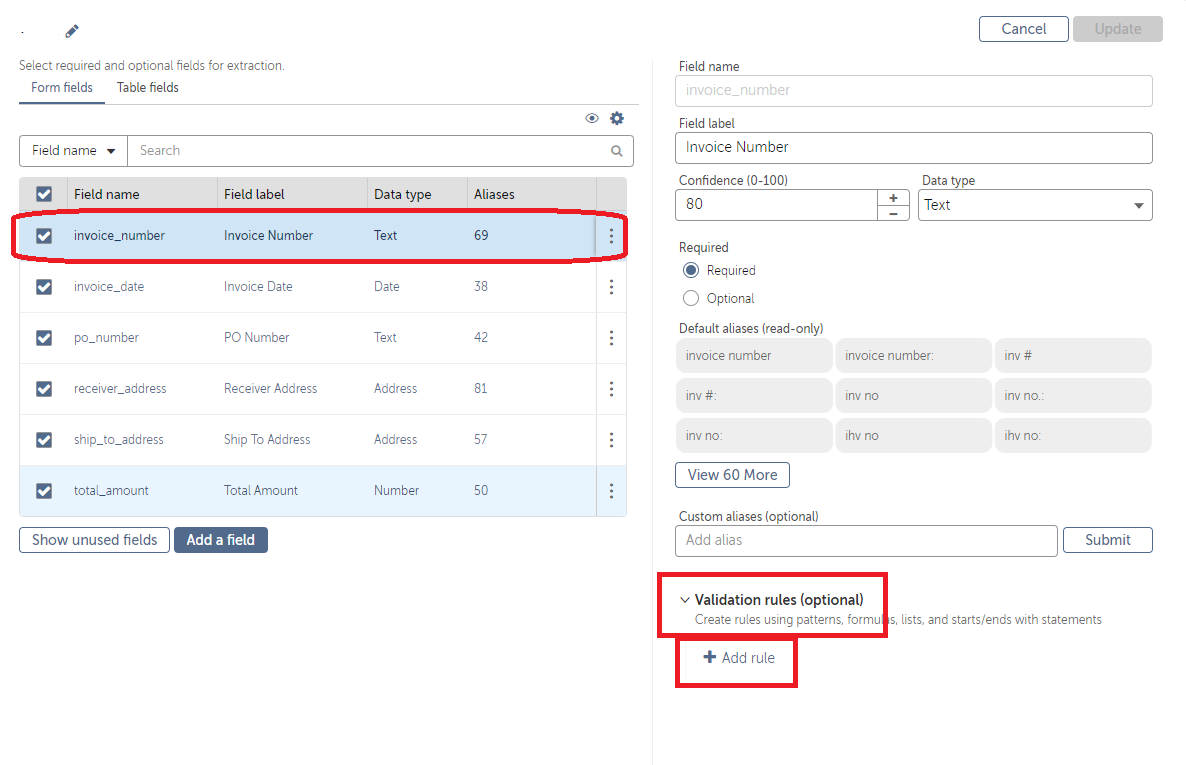
Step 5: Train the IQBOT model
Once the extraction rules are defined, you need to train the IQBOT model. This step is essential because it helps the system to understand the patterns and structures of the invoices. To train the IQBOT model, click on the “Train IQBOT Model” button.
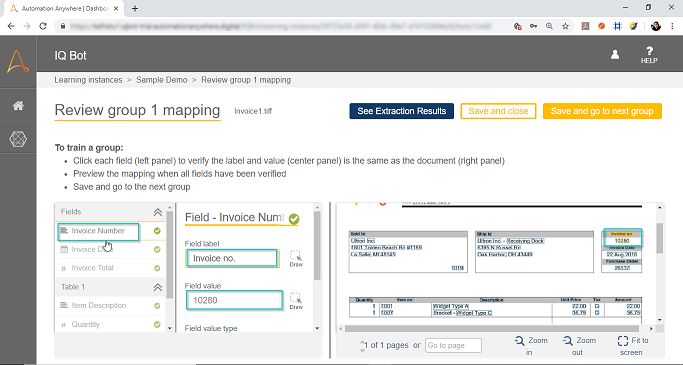
Step 6: Validate the extraction results
After the IQBOT model is trained, you need to validate the extraction results. Validation is an essential step because it helps to ensure the accuracy of the extracted data. To validate the extraction results, click on the “Validate Results” button.
Step 7: Review the extracted data
Once the extraction results are validated, you can review the extracted data. You can do this by clicking on the “Review Extracted Data” button. This will show you a summary of the extracted data.
Step 8: Export the data
Finally, once you’re satisfied with the extracted data, you can export it in the format of your choice. To export the data, click on the “Export Data” button and select the format you want to export it in.
Important considerations when it comes to Straight-through Processing (“STP”)
It is possible to configure IQBot to skip data validation during invoice processing, but it may not be the best practice in most cases.
Data validation is an essential step when using IQBOT in the invoice processing workflow as it ensures the accuracy of the extracted data before it is used for downstream processes like payment or accounting.
Skipping data validation can lead to errors in the data, resulting in incorrect payments, disputes with suppliers, or compliance issues.
However, there may be cases where skipping data validation may be acceptable.
For example, if the extracted data is used for informational purposes only and not for any downstream process, data validation may not be necessary. In such cases, the organization may choose to configure IQBot to skip the data validation step.
Skipping data validation altogether is not recommended, but rather organizations should evaluate their specific needs and requirements to determine the appropriate level of validation needed for their invoice processing workflows.
If you want to learn more about Straight-through Processing (“STP”) and the drawbacks of using confidence levels in STP, check out our webinar here.
Processing Invoices with DocDigitizer
Here is a step-by-step tutorial on how to use DocDigitizer API to process invoices.
Please note that you will need an API key to authenticate; please ask for one here.
Step 1: Setup Document Injection
The process starts with inbound files (.pdf, .jpg, .tiff, or .png) into DocDigitizer’s Data Extraction engine.
The API endpoint to support this is: https://api.docdigitizer.com/api/v1/documents/annotate (documentation available here)
Here is a code Python sample snippet:

As an output of calling /API/v1/documents/annotate, you will get a synchronous JSON response with the acceptance of the request alongside the document_id (unique identifier of that document) and the sla_moment (max lead time for this document’s data to be available)
 From this point on, the process will be asynchronous, which means that your extraction data will not be available in real-time.
From this point on, the process will be asynchronous, which means that your extraction data will not be available in real-time.
If you provide a callback URL when submitting the document, you can be notified about the status of your document.
Step 2: Document Classification and Data Extraction
Unlike IQBOT, DocDigitizer does not require any upfront training or setup; DocDigitizer offers an all-inclusive IDP delivery process that includes a built-in human-in-the-loop expertly designed training on-the-fly process.
For invoices DocDigitizer offers a standard out-of-the-box data schema, covering +20 fields, including line items. You can find the detailed documentation of this data schema here.
DocDigitizer will perform field by fields extraction and leverage multiple OCR engines and its proprietary ML models with a backup built-in Human-in-the-loop.
The models will start with the lower confidence fields that require Human-in-the-loop quality control and use the correction resulting from this quality control to enhance the extraction of the following fields.
By doing this field-by-field, multi-pass approach, learning can be done within the document being reviewed, speeding up the overall learning cycle and reducing lead time because multiple fields may be processed in parallel.
This step produces a (near) 100% accurate, trusted, and verified set of data for the submitted document.
Step 3: Getting Back Data
Once the processing of the document is ready, data can be queried using the POOL or PUSH method.
If you upload your document with a callback, then it will be triggered with the document ID, and you will know that you can query back the data.
If you did not use the callback, then you need to create an update cycle that queries DocDigitizer API occasionally, checking if the results are available.
The API endpoint to support this is: https://api.docdigitizer.com/api/v1/documents/<replace with your document id> (documentation available here)
Here is a code Python sample snippet:

As an output of calling /api/v1/documents/documents you will get a synchronous JSON response with the status of your processing request and, if it is ready, with the document’s data under: “annotations”/”data” on the JSON output.
IMPORTANT NOTE: Please always check that the reviewed flag is set as TRUE (“reviewed”: true). This is how you know that your data is ready to be consumed. If it is false, then your should wait and try again later.
API Demo
Frequently Ask Questions
- What is the processing lead time?
- DocDigitizer has several lead-time options when you create your subscription, but on average, the transaction may take a few minutes to be fully processed.
- How can I check the processing lead time?
- Within the API response, you have information that may help you, namely the transaction creation timestamp and the timestamp when the processing was concluded.
- Where can I check the confidence levels?
- All data will be outputted according to DocDigitizer quality SLA of +99% accuracy. With this all-inclusive approach of having the human-in-the-loop built-in, it is not expected for the user to deploy any additional validation. Therefore, there is no need for confidence levels.
- How can I modify the data schema?
- You can change and adapt your data schema in your subscription settings.
Conclusions
When it comes to processing invoices specifically, IDP tools such as IQBOT (from automation anywhere) and DocDigitizer can be used with significant success. By leveraging these tools, organizations can achieve greater efficiency and accuracy in accounts payable while freeing up resources to focus on more value-added activities.
IQBOT and DocDigitizer present entirely different approaches to delivering their IDP service. We cannot say one is better or worse than the other because, at the end of the day, it will strongly depend on the approach you are willing to take on your IDP journey.
When using IQBOT, you will be buying a technology tool. You will be required to spend time setting up this tool, and once you go live, you will need to have a Human-In-The-Loop backup to check the right information and correct the wrong one.
When using DocDigitizer you will be buying the outcome, the (near) 100% accurate data. All the processes will be supported in an all-inclusive black box that will take care of all complexities on your behalf.
The asynchronous nature of DocDigitizer API may demote some users that are looking to get real-time results. Still, it’s highly unlikely that any Intelligent Document Processing (IDP) tool can provide 100% accurate results in real-time for every document or data point.
So to be sure you are comparing apples with apples, you need to measure the processing lead time for the process as a whole. When processing a batch of 1000 invoices, how long will it take to get as close as possible to 100% accurate data?
- IQBOT – It will take hours/days – requiring you to review most of the documents using your own HITL.
- DocDigitizer – It will take a few minutes – allowing you to process your documents in STP and not require any validation on the customer end.
In the case of invoices, due to the layout variability, DocDigitizer may bring some advantages if you look to deploy Straight-through Processing Automation because it will remove the need for you to deploy your Human-In-The-Loop quality control, which often accounts for 55% of the implementation cost.
Moreover, the go-live cycle may be shortened from months to a few days due to the training-on-the-fly capabilities provided by DocDigitizer without the need for you to deploy your IT staff which sometimes is scarce.
Book a meeting and learn more about how you can start your all-inclusive journey.